機器學習演算法 – K 近鄰
K 近鄰(K Nearest Neighbors),我們簡稱 KNN,他是機器學習當中最簡單也 是最直觀的演算法。其觀念是根據資料彼此之間的距離進行分類,距離哪一種類 別最近,就分到哪一類,所以 KNN 常被用於分類問題。
如下圖 1,KNN 分類演算法的分類預測過程十分簡單並容易理解:對於一個 需要預測的輸入向量 x,我們只需要在訓練資料集中尋找 k 個與向量 x 最近的向 量的集合,然後把 x 的類別預測為這 k 個樣本中類別數最多的那一類。如圖所 示,ω1、ω2、ω3 分別代表訓練集中的三個類別。其中,與x𝑢最相近的 5 個點 (k=5)如圖中箭頭所指,很明顯與其最相近的 5 個點中最多的類別為ω1,因此, KNN 演算法將x𝑢的類別預測為ω1。
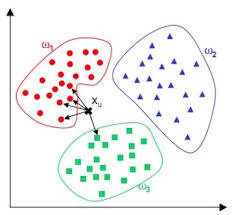
圖 1. KNN 演算法分類示意圖(K=5 結果) (圖片來源)
- KNN 的演算法步驟如下:
- KNN 中的 K 代表找出距離你最近的 K 筆資料進行分類。
- 假設 K 是 3,代表找出前三筆相近的資料。
- 當這 K 筆資料被選出後,就以投票的方式統計哪一種類的資料量最多,然後就被分到哪一個類別。
思想與「近朱者赤,近墨者黑」有異曲同工之妙!
- KNN 演算法情境舉例:
政治大學是一間強調因材施教的學校,其教育方針是儘量將同質性高的學 生分成一組,然後進行教學,你如果是一位導師,在新學期收到一位轉學 生,你如何替他/她分組?分組的方式有很多種,例如:此學生傾向於理工 思考、文組思維?你要用什麼樣的方式,將新學生編入適合的組別?- 作法:給這位學生考試,發現數學 90 分,國文 50 分,是不是就傾向理工組了呢?
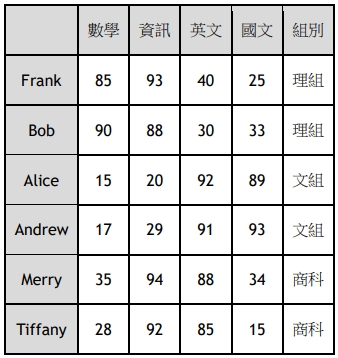
▼ 如下表一為政治大學分組考試後,六位學生針對四個科目的考試分數,學校 會依照這個分數來分發所屬的組別。
表一. 學生考試對應所屬組別
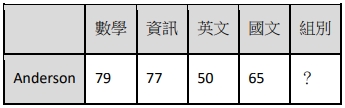
今天有一位轉學生進來叫 Anderson,也進行了這項分組考試,他的分數如下表二:
表二. 新同學考試結果,要分配哪一個組別?
我們將套入 KNN 演算法步驟:
假設政治大學使用 KNN 將學生做分組(K = 3),那麼 Anderson 入學之後會被分 到哪一組?
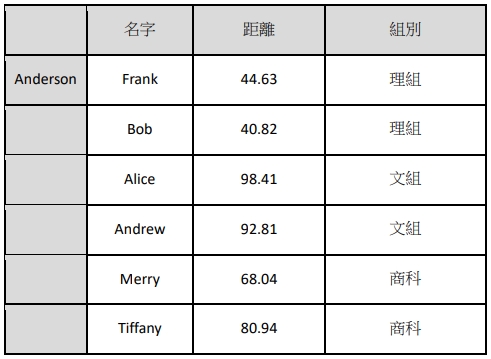
- Step1:計算距離(歐氏距離):我們將 Anderson 的考試分數與其他每一 位考生之分數距離來計算,如下結果:
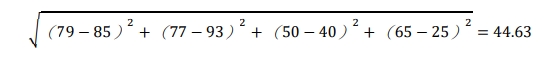
所以 Anderson 與 Frank 之間分數距離為 44.63,距離越小代表性質越相近 (理想值為 0)。
因此我們將 Anderson 對應每一個學生的分數距離都算出 來,如下表三所示:
表三. Anderson 與每一位學生的分數距離
- Step2:選取距離較近的 K 個鄰居
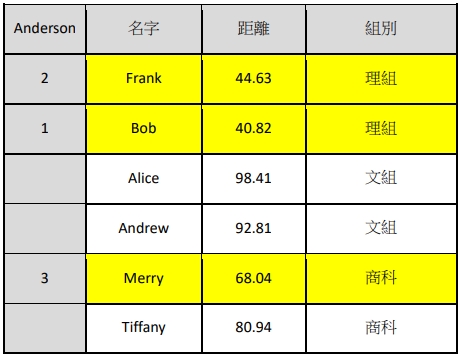
從 Step1 中計算出分數距離,我們可以發現最近最相近的三位學生分別是 Frank, Bob, and Merry,
對應的組別是理組、理組、商科,下表四所示:
表四. 選取距離較近的 K 個鄰居(K=3)
- Step3:
我們選出三個科目:理組、理組、商科,進行投票,可以得到結果, 如下表五:
理組2票、商科1票
因此 Anderson 就會被歸類在 「理組」
表五. Anderson 歸類組別結果

以上,就是整個 KNN 的執行過程,新輸入的資料就可以透過 KNN 分群或是分類到適合的群組與類別,而且其分類精確度非常高,很被廣範應用喔!是常被推廣 的演算法。
◎ 想想看:
1. 如果今天 Anderson 每一科滿分,他要被分到哪一組?有哪些解決方法?
◎ 補充與延伸:
- 前面我們用 K = 3,當作例子,我們再進一步去分析,如下圖 2:
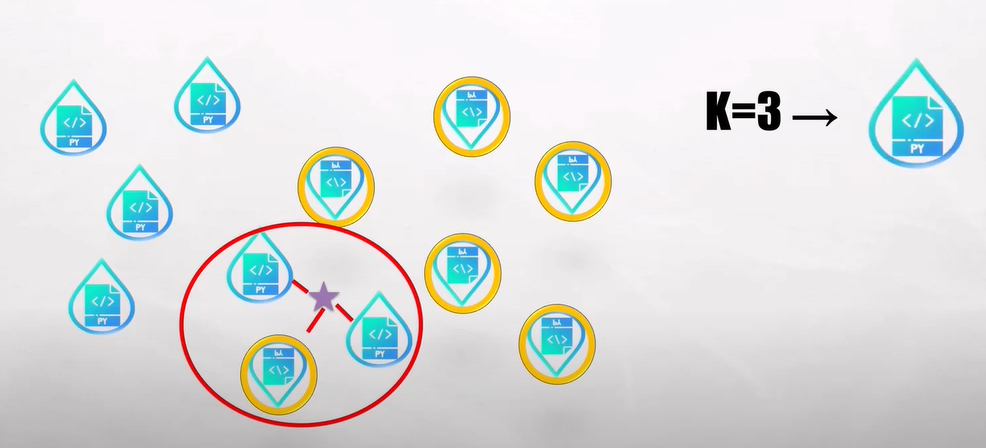
圖 2. K=3 分類示意圖 (圖片來源)
- 那今天選擇 k = 5 情況下,如下圖 3:
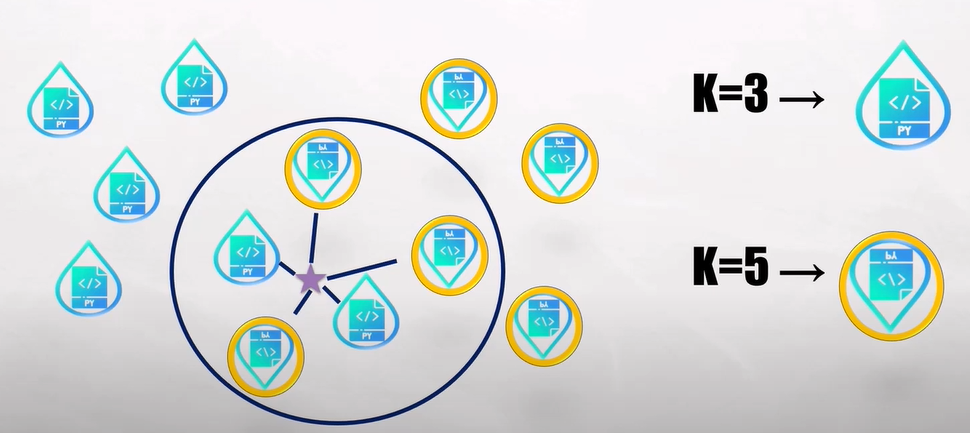
圖 3. K=5 分類示意圖 (圖片來源)
- 我們來看 k = 4 的情況,一樣我們會去計算距離,如下圖 4:
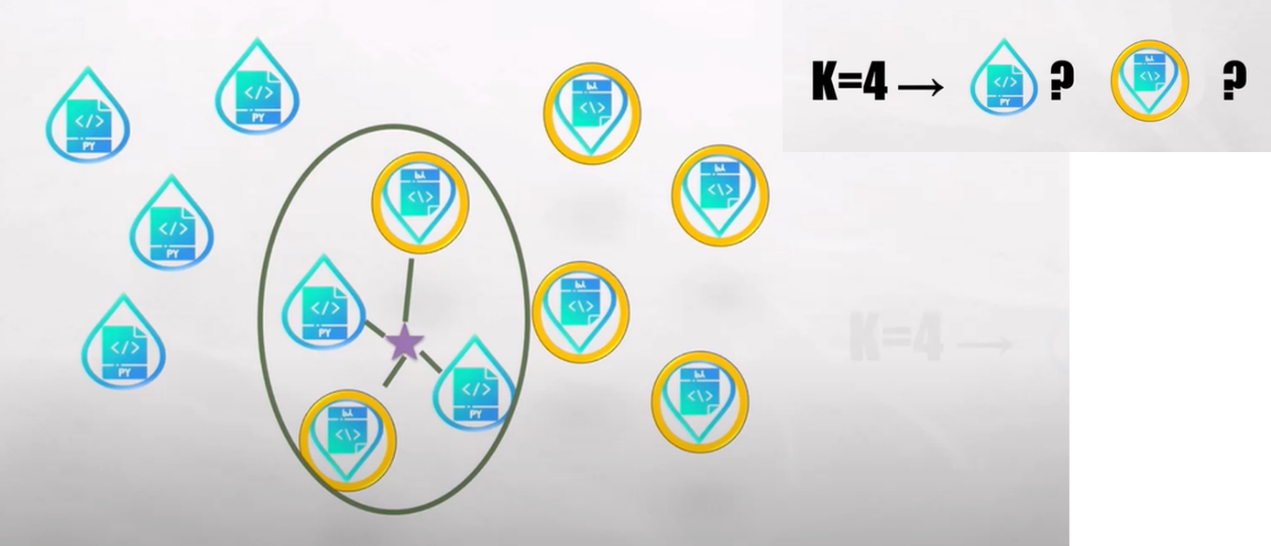
圖 4. K=4 無法分類結果 (圖片來源)
我們發現結果投票各占一半,k = 4是沒有答案的
因此在使用 KNN,在選擇 K 的時候,通常不會選偶數。
如果我們一直遇到每票且票票等值的情況下,要如何解決?
- 答:使用「加權投票法」,概念: 距離近的給予比較高的權重,因此在 K = 4 如下圖就會判定歸類藍色水滴類別。

圖 5. K=4 無法分類結果 (圖片來源)
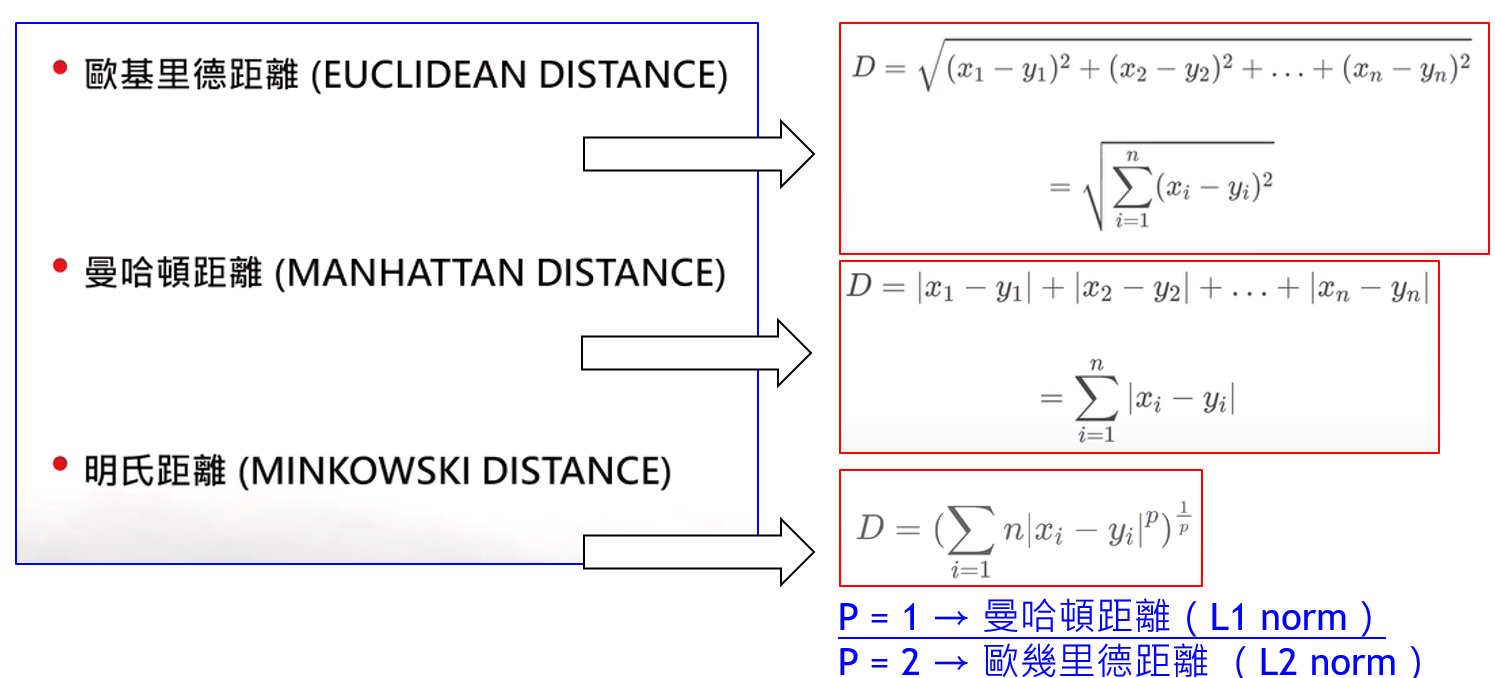
前面所述距離,我們使用歐氏距離(歐幾里德距離),求空間中兩點之間距離計 算大小,如下我們也可以用其它公式來計算兩點距離:
總結:
- 所以 KNN 不只可以處理離散型的資料,想可以處理連續型的資料。
- K值選擇為預測準確程度的關鍵,且最好選擇奇數以避免投票平常手的狀 況發生。
- K 值越大,可能會包含不相關的樣本點進來,K 值太小又會被會為是噪 音的干擾(雜訊),因為參考的樣本數不夠多,通常都會把 K 值控制在 樣本數平方根以下,是最好的結果。
- 因為我們不知道哪一個 K 值是最好的,我們可以去切割樣本去做交叉 驗證找到適合的 K 值。選擇適合的距離計算方式。
KNN 的優點:
- 簡單易懂
- 資料型態不受限(離散型:取眾數,連續型:取平均值)
- 在多種類別預測有較好的表現
KNN 的缺點:
- 計算本成本高:因為他要不斷地計算點跟點之間的距離
- 資料不平衡時容易產生預測不準確的狀況發生
參考資料
選擇的能力 – 探索人工智慧的核心 陳永維 李厚均 著 TKB
撰文者:政大人工智慧與數位教育中心 黃啟賢研究員