深度神經網路基本運作原理
近年來運算速度的加快與運算成本降低,神經網路研究有驚人的突破,其中最常見的網路,就是深度神經網路(Deep Neural Network, DNN)。例如,ILSVR(ImageNet Large Scale Visual Recognition Competition)是由ImageNet所舉辦的年度大規模視覺識別挑戰賽,自2010年開辦以來,全球各知名AI企業莫不以取得此項比賽最高名次為殊榮,以宣告其圖像辨識技術已達登峰之境。ILSVRC競賽所使用的dataset來自於ImageNet。ILSVRC每年會從超過1400 萬張full-sized且標記的相片中取出部份樣本進行比賽。競賽中評比的Top-5 error rate分數,其計算方式是每位參賽者針對某張圖片進行預測,所給出的五個最有可能的預測中若有一個為正確就算答對,若沒有一個正確則算錯誤,直至2017年基於DNN結構延伸的SENet已可達低於5%的錯誤率(error rate),比人的辨識錯誤率更低,如下圖1:
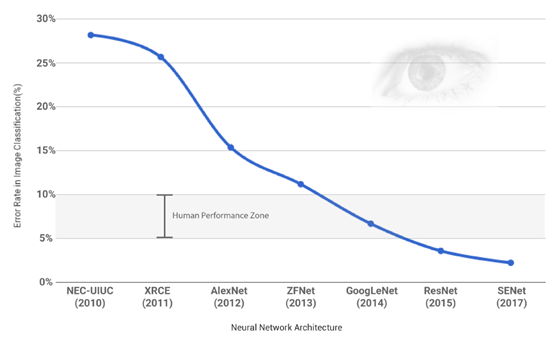 |
圖1. ILSVR(ImageNet Large Scale Visual Recognition Competition)是由ImageNet所舉辦的年度大規模視覺識別挑戰賽
(橫軸:不同年度推出的神經網路模型,縱軸:辨識錯誤率)
A. DNN 架構介紹
DNN 的最小單元,我們稱「神經元」,如下圖神經元的結構,我們可以用數學公式去模擬人腦,其結構非常簡單,共有三個組成元素,如圖2:
- 權重(weight, w)
- 偏壓(bias, b)
- 激勵函數(activation function, δ)
神經元結構允許多個輸入與一個輸出,每一個輸入對於結果的影響程度不同,所以需要靠各自的權重來區分輸入的重要性。而激勵函數就像一個 on/off開關,偏壓值 b 為一個修正值,當我們無法決定神經值的激勵門檻,就可以靠偏壓值 b 來修正,如公式(1)。
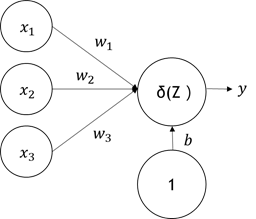 |
圖2. 神經網路基本架構
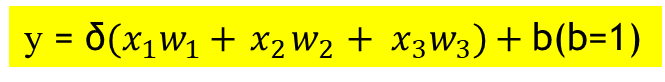 |
|
B.我們來談談什麼是激活函數(activation function, δ)
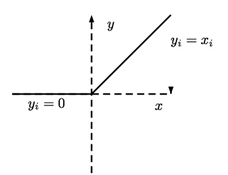
- ReLU (Rectified Linear Unit, ReLU),如圖4所示。
- ReLU特性:輸入若小於0,輸出就是0,輸入若大於等於0,即輸出等於輸入。
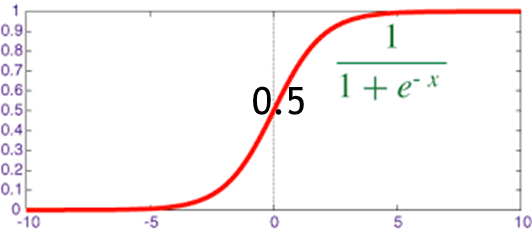
- Sigmoid,如圖5所示。
- Sigmoid特性:輸入若小於0,在-5至0的區間允許一些值輸出,會比ReLU有彈性一點,若是 >> 0 的情況,輸出值近似於1,反之遠小於-5值,輸出即為0。
|
|
|
|
圖4. ReLU 函數 |
圖5. Sigmoid函數 |
在人腦中,約有1500憶個神經元細胞,它們彼此連結並且能在短時間內解讀外界的刺激訊號,在電腦中,我們如何將神經元彼此組建起來呢?
- 答:全連接層(Fully Connected Layer)
全連接的意思是讓神經元彼此互相連接,簡單結構如下圖6,輸入層有3個維度,輸出層2個維度。
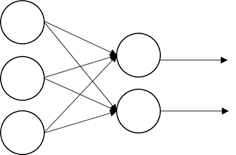 |
圖6. 全連結層基本結構圖
有了神經元基本概念後,我們將開始建構一個全連接層,將其擴大,DNN就是不斷把新的全連接層疊加起來變得更高(上、下)或是更深(左、右),模擬成複雜大腦的結構,如下圖7:
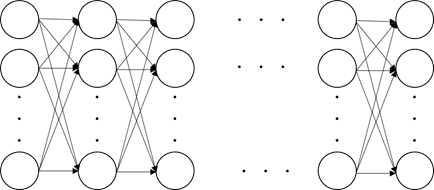 |
圖7. 全連結接(高、深的DNN)架構
DNN 分為輸入層(input layer)、隱藏層(hidden layer)、輸出層(output layer),圖8所示:
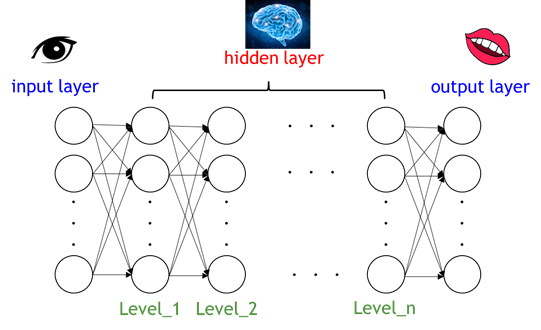 |
圖8. 輸入層、隱藏層、輸出層深度全連接層完整架構
我們理解了DNN架構後,我們可以把DNN想成是一個大腦,我們將說明手寫數字影像辨識的過程,如圖9模擬架構,深度神經網路模型植入電腦,讓電腦擁有辨識手寫數字的功能:
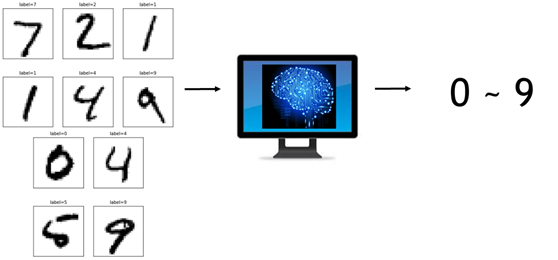 |
圖9. 手寫辨識AI模擬示意圖
C.DNN運作原理
5個步驟:
- Step1定義資料
- Step2 定義DNN
- Step3定義輸出函數
- Step4定義代價函數
- Step5優化函數(權重)
Step1定義資料
如下我們要判斷0, 1, 2 的資料,並將每一筆影像所對應的數字標示出來(label),資料越多越好,於是我們蒐集10000張,如圖10。
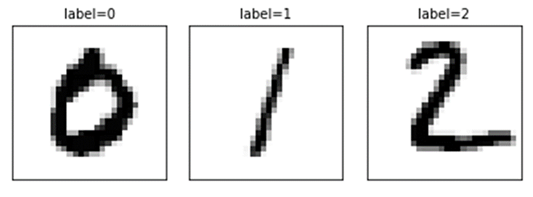 |
圖10. 影像標註範例圖
我們會將10000張資料分成兩部分,分別是訓練資料(training data)與測試資料(test data)
- 訓練資料:讓DNN網路學習,使其達成某個特定的工作(例如:辨識出數字影像的DNN)
- 測試資料:當我們訓練好辨識數字的DNN,用來驗證正確率的高低。
訓練資料與測試資料比例分別要多少?
- 答:通常8:2, 或 7:3,根據資料的分佈去調整
當資料被定義完之後,我們會對訓練資料集執行對應的數字一位元有效編碼(one-hot encoding)。所謂一位元有效編碼就是把資料所有的可能性「完全展開」,假設有10個數字,就會需要10個位元來儲存,如下圖11範例。
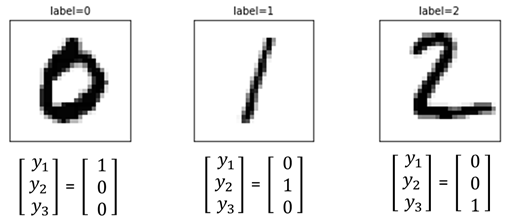 |
圖11. 影像標註數字一位元有效編碼
Step2定義DNN
定義完資料後,我們就要來建構DNN,而DNN我們會分成三層:輸入層、隱藏層、輸出層。我們將一筆資料[0.6, 0.2]送入DNN 訓練過程,激勵函數用ReLU:
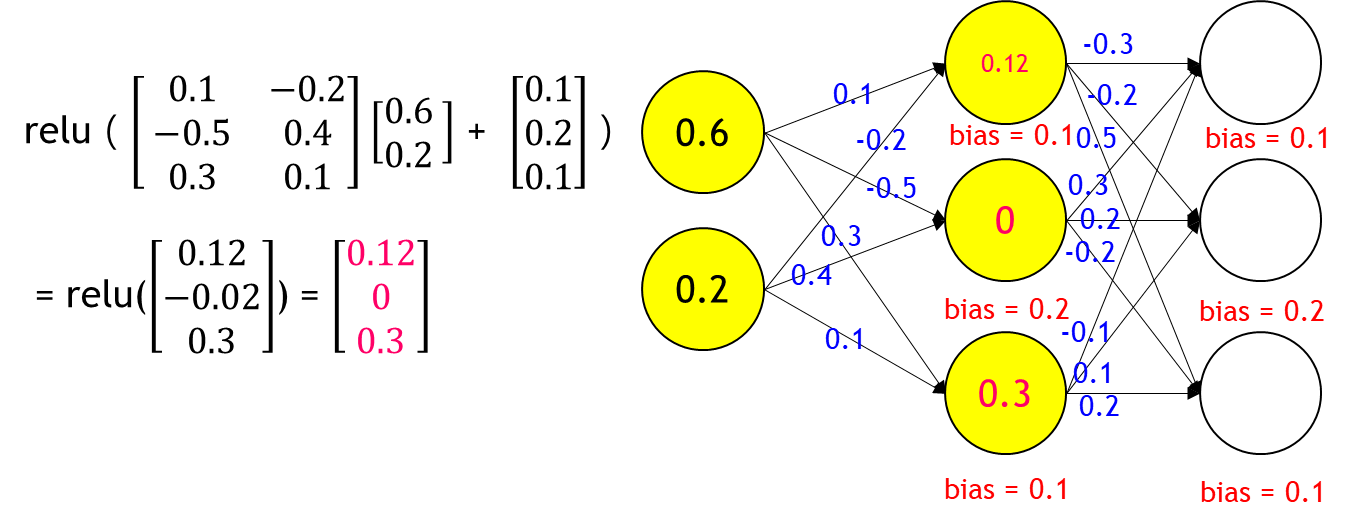 |
 |
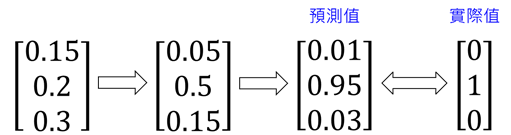
Step3定義輸出函數
DNN在對資料進行預測後,會輸出預測值[![]()
![]() ] ,這些預測值內的數值不會像one-hot encoding這麼整齊(只有某一位置是1,其他位置都是 0),而是一堆雜亂的數字,為了讓這些預測值可以與實際值比較,我們需要調整這些值,我們叫做正規化,正規化的結果為機率分佈的向量。因此我們要用softmax這個函數來調整。Softmax(
] ,這些預測值內的數值不會像one-hot encoding這麼整齊(只有某一位置是1,其他位置都是 0),而是一堆雜亂的數字,為了讓這些預測值可以與實際值比較,我們需要調整這些值,我們叫做正規化,正規化的結果為機率分佈的向量。因此我們要用softmax這個函數來調整。Softmax(![]() ) 如公式(2):
) 如公式(2):
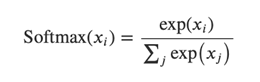 |
…公式(2) |
![]() :輸入向量,
:輸入向量,![]() 為向量中的元素值。
為向量中的元素值。
- 例如:如給予一組向量 x =
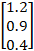 , 使用softmax函數算出結果?
, 使用softmax函數算出結果? - Sol:
softmax ( 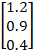 ) = ) = |
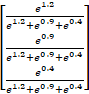 = = |
 |
![]() (自然指數)
(自然指數)
因此,我們可以將其結合我們的深度神經網路,如下圖12:
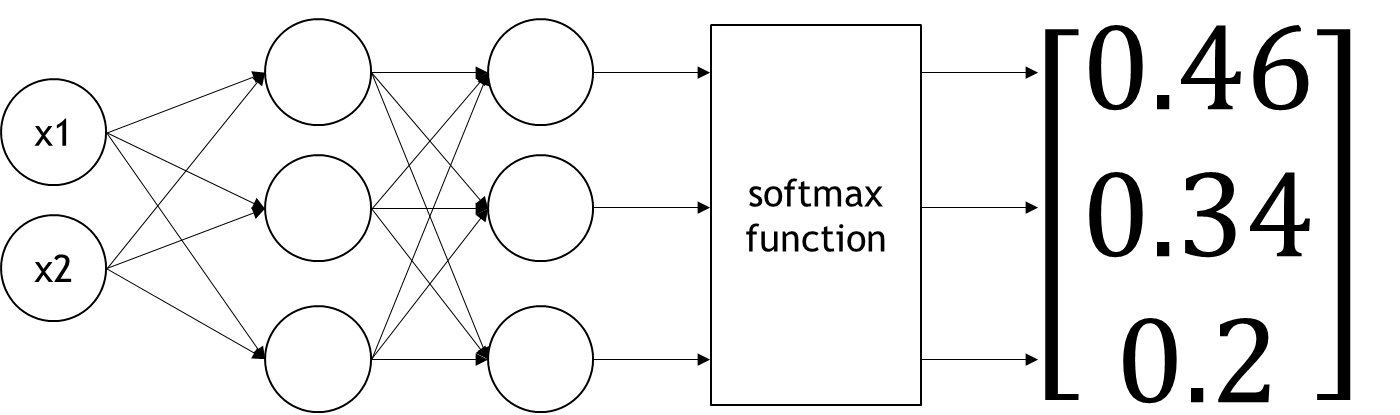 |
圖12. 結合softmax層後得到機率分佈之完整神經網路結構
經過softmax轉換後,我們可以將預測值轉換成機率分布,這個步驟對於接下來的代價函數(Loss function)使用非常重要,唯有將預測值轉換成機率分布,才能與實際值比較。
Step4定義代價函數
- 最小平方差MSE (Mean Square Error)
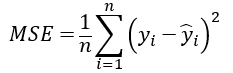 |
…公式(3) |
![]()
- 交叉熵(Cross Entropy)
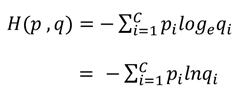 |
…公式(4) |
![]()
例:假設一個DNN的實際值 p = [0,1,0],預測值 q = [0.333, 0.5, 0.167] (數字為1的影像),這兩個值都符合機率分布(加總和為1),我們使用公式(4)cross entropy 計算差異如下,這個值若趨近於0,代表相似度越高。
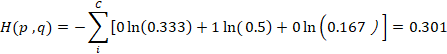 |
上述案例對應到DNN的物理意義是:一張數字為1的影像丟到DNN做計算,它的輸出經過softmax函數的處理後已符合機率分布的向量 q = [0.333, 0.5, 0.167] , 這個向量會與實際值 p = [0, 1, 0] 進行cross entropy 運算,運算結果代表預測值與實際值的差距,這個數字越小,預測結果越正確,越接近答案。
Step5優化參數(神經網路權重調整)
優化參數的意思是,在DNN模型中不斷調整參數與學習率,使得預測值跟接近實際值,優化方法可以用「梯度下降法(微分) 」、「反向傳播法(微分)」,這邊我們不贅述。
 |
整合前面所述:整體架構呈現如下圖13:
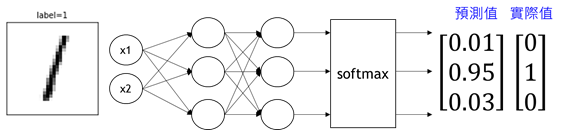 |
圖13. DNN手寫辨識整體架構圖
優化之後,可以發現預測值變成0.95(影像為1的圖片)與one-hot encoding的實際值對應,我們可以用MSE或Cross entropy計算代價函數,若代價函數值趨近於0,則代表判別是1的影像越高,結果是正確的。
結論:讀完本篇,同學們可以知道如何訓練DNN模型,如果使用supervised learning 方法,需要完整的公開資料集,不然就要自己用label tools 方式去定義新的資料,通常定義新的資料編碼我們會使用 one-hot encoding,但也有別的方式,同學們可以上網找找其它方法,有了完整的資料集之後,我們會將其輸入定義好的模型結構,輸出函數、代價函數、優化函數要選哪一個,一開始都要設定好,才能進行模型訓練,這就是一個基本訓練深度學習模型的過程。
參考文獻
- 陳永維 李厚均(2019)。選擇的能力 – 探索人工智慧的核心。大碩出版。
- 李宏毅(2021 年)。【機器學習2021】(中文版)。https://www.youtube.com/playlist?list=PLJV_el3uVTsMhtt7_Y6sgTHGHp1Vb2P2J
撰文者:政大人工智慧與數位教育中心 黃啟賢研究員