半監督式學習(Semi-Supervised Learning)介紹
|
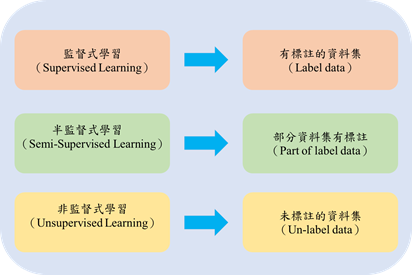
機器學習領域,通常分為監督式學習(Supervised Learning)與非監督式學習(Unsupervised Learning),監督式學習,其資料集的特色為有註釋標籤(label),而非監督式學習的資料集是沒有註釋標籤,所謂的半監督式學習(Semi-Supervised Learning),是部分資料是有註釋標籤。現實世界中,通常遇到的情況是沒有標籤的資料遠大於有標籤的資料,這也接近我們實務上所操作的資料,我們從不缺資料,缺的是有標籤的資料,就像我們可以用手機拍很多照片,但是他們都是沒有標籤的資料。
機器學習跟人類的學習非常相似,要讓機器(電腦)跟人類一樣有學習能力,通常我們會先把資料分類(Classification),再進行分析(Analysis)、判斷(Judgement)、最後採取行動(Action)。而有標籤的資料就是告訴機器標準答案,機器再進行測試資料的時候會依照標準答案作答,正確性會比較高,例如:我們要訓練機器區分貓和狗的圖片,我們要提供十幾萬張貓和狗有註釋的照片,機器會依照註釋的照片去偵測貓和狗的特徵,依照特徵辨識出貓和狗的預測結果。
然而,註釋大量的照片是非常耗人力成本與時間,在標註的過程中也有可能標示錯誤,例如:將貓的圖片標示成狗,等同於告訴你錯誤的答案,這會嚴重影響預測結果,因此機器學習的研究發展朝向非監督式學習的路線;非監督式學習就是不告訴電腦標準答案,要求電腦學習預測正確的結果,但這是非常困難的,因此有學者提議半監督式學習,也就是對少部分資料進行「註釋」或「標註」,電腦只要透過少數註釋的資料找出特徵,就可以做到分類預測的效果,例如:在1000張的照片中,我只要註釋100張哪些是貓哪些是狗的照片,機器透過這100張照片的特徵,去辨識及分類剩餘的照片,因為已經有辨識的依據,所以預測出來的結果通常比非監督式學習準確,如下圖為機器學習類別對應資料集的特性示意圖。 不同機器學習類型所對應的資料集特性
撰文者:政大人工智慧與數位教育中心 黃啟賢研究員 |